

Suppose you were offered a futuristic virtual reality system on par with The Matrix for just $100. You would purchase it, right?! Now imagine you needed 50,000 sq. ft. of space in your home to run the system. That would change the proposition quite a bit.
In many ways that analogy holds for modern face recognition (FR) algorithms. While accuracies have improved dramatically, the resources required to deploy a given solution varies dramatically by vendor.
Amongst the 70 most accurate NIST FRVT Ongoing algorithms in the Nov. 2018 report, there were the following fluctuations in efficiency metrics:
- 15x difference in how fast images could be processed for facial detection and vectorizing (i.e., enrollment)
- 40x difference in the length of the facial vector / template (i.e., template size)
- 220x difference in the time it takes to compare two templates (i.e., comparison speed)
These differences in efficiency can cause hardware cause costs to soar or wholy prevent an application concept, which should concern anyone procuring a face recognition algorithm.
This article will equip you with the knowledge to assess the efficiency requirements of your face recognition system. In turn, you will be able to factor this important consideration into your procurement process and potentially eliminate certain algorithms before the time consuming step of performing internal evaluations.
Enrollment speed
Enrollment is the process of detecting faces in an image (or video frame) and creating templates that encode the identifying characteristics of each face. It is one of the two steps performed in automated face recognition, and can play a critical role in system design.
The faster the enrollment speed, the less computing power required. Unfortunately, as shown in the following histogram, enrollment speeds vary considerably across face recognition algorithms:
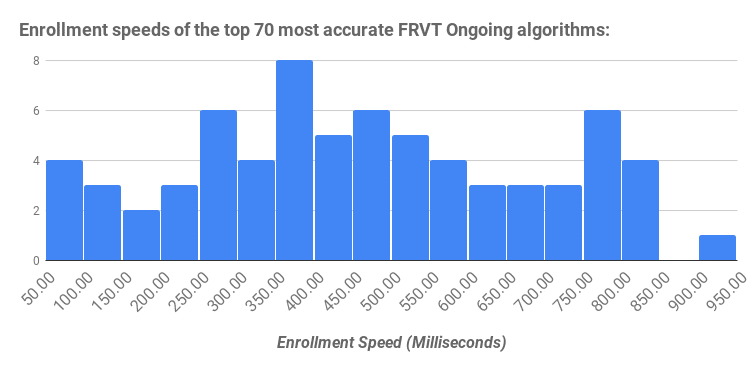
The enrollment speeds provided in the histogram are from Table 1 in the November 2018 NIST FRVT Ongoing report, which measures enrollment speeds on images with a single face.
It is important to note enrollment speed is generally a function of the number of faces in an image that need to be templatized, and, to a lesser extent, the size of the image (or video frame). Thus, if an image has five faces present, it will take significantly longer to enroll than an image with one face present (usually five times as long).
The reason the number of faces in an image is the primary factor for enrollment speeds is that for modern algorithms the representation step of the enrollment process is generally slower than the face detection step. The duration of the representation step will increase directly as a factor of the number of faces in the image. The duration of the detection step changes based on the size of the image and the minimum face size considered.
Enrollment speeds have important implications for the following applications:
-
- Video processing
While most cameras capture at a rate of 30 frames-per-second (FPS), typically 5 FPS will suffice for face recognition algorithms. Depending on the enrollment speed of an algorithm, enrolling 5 FPS can make a major difference in the number of CPUs required for real-time processing. Particularly so when each frame may have multiple faces.
For example, if an algorithm takes 800ms to enroll a frame with one face, then to process 5 FPS in real-time would require nearly 5 CPU cores. By contrast, an algorithm that has an enrollment speed of 150ms would be able to perform real-time processing on just 1 CPU core. - Enrolling a search database
For search applications, templates must first be generated for each image in the database. The time it takes to enroll a database will be a function of the number of images in the database, the enrollment speed, and the number of CPU cores available.
For example, let’s say a database of 10M images, each with a single face, needs to be processed for search and the system is powered by an 8 CPU core server. An 800ms algorithm is going to require 800ms * 10e6 images / 8 cores = 11.5 days. By contrast, a 150ms algorithm requires only 2 days (assuming there is no bottleneck reading the images from storage). - Re-enrolling a search database:
When a vendor ships an improved algorithm it is typically the case that all of the database templates must be re-generated from the original images. And, given the massive rate of improvements in face recognition algorithms, database re-enrollment is more important than ever.
To be clear, it is not the case that a system has to be updated every time a new algorithm is made available by a vendor. Further, some face recognition vendors unfortunately do not make algorithm updates readily available, or they are simply not innovating enough for there to be meaningful algorithm updates. However, assuming that you have (hopefully) selected a vendor that is delivering accuracy improvements on pace with the rest of the industry and you have licensing rights to these updates, at some point you will want to re-enroll your database to create templates from a newer version.
The same time calculation for enrolling a database applies to re-enrolling it. A faster enrollment speed may be the difference in re-enrolling over the weekend on the same hardware that hosts the system, or having to purchase a separate server to perform re-enrollment over the course of a few weeks. - Enrolling a probe image:
For both 1:N search and 1:1 identity verification applications, the probe image needs to be enrolled prior to searching it against the gallery (1:N), or compared against the claimed identity (1:1). Often times this enrollment is trivial because it is only a single image, however there are several cases where slow enrollment speeds can become an issue:-
- Mobile devices: ARM processors, common in mobile devices, typically see enrollment slow by a factor of 2x to 3x.
- Battery powered devices: the less time enrollment takes, the less power consumed. If face recognition is persistent (e.g., mobile device unlock), slower enrollment speeds can result in unreasonable usage of the limited battery capacity.
- Time-sensitive applications: As enrolling the presentation image is but the first step in a subsequent application (e.g., search or compare), if an application requires a quick turn-around, then slow enrollment speeds with negatively affect the user experience.
-
- Video processing
Template Size
Templates store the facial identity measurements needed to compare two faces. A critical software system design concept as it pertains to template size is the speed difference when reading data (e.g., templates) from different storage mediums. Specifically, the read bandwidth of RAM versus persistent storage (e.g., a hard-drive or network/cloud storage) can range from 20x to 1000x. Even at 20x difference, this means searching templates stored on disk would be 20x slower than those loaded into RAM.
Due to the above considerations, galleries of templates are first loaded into RAM before being searched. When this is performed the bottleneck for searching typically becomes compute bound as opposed to the I/O bound.
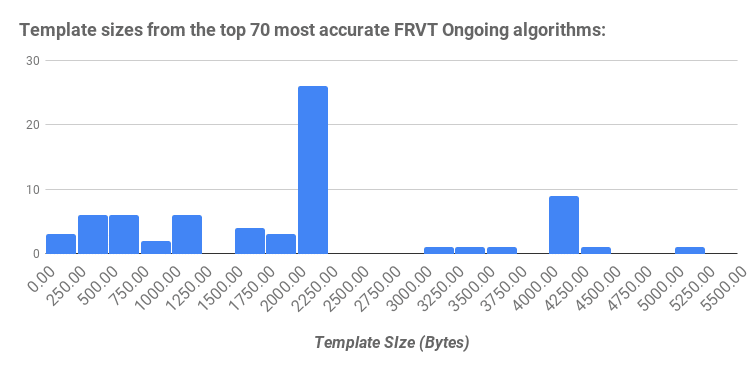
RAM is an expensive resource, particularly when a lot is required. The larger the template size the more RAM required, meaning the distribution of template sizes shown in the histogram above is directly indicative of the amount of RAM required to host search applications.
As an example, let us again consider a database of 10M faces. In this instance, we will consider two different algorithms, one with a template size of 200B (bytes) and one with 2,500B (2.5KB). These template sizes are within the distribution of template sizes by top-tier vendors in the NIST FRVT Ongoing tests.
- In the case of the 200B algorithm: 200 bytes * 10M templates = 2GB of RAM required to load the templates.
- In the case of the 2.5KB algorithm: 2,500 bytes * 10M templates = 25GB of RAM required to load the templates.
These differences in template size can equate to significantly higher hardware costs for a face recognition system.
Comparison Speed
Comparison speed is similar to template size in that it is quite important in search systems.
For search applications, a reference template is typically compared against every template in the gallery in order to find any matches. Thus, for every gallery template, a comparison must be performed between it and the probe.
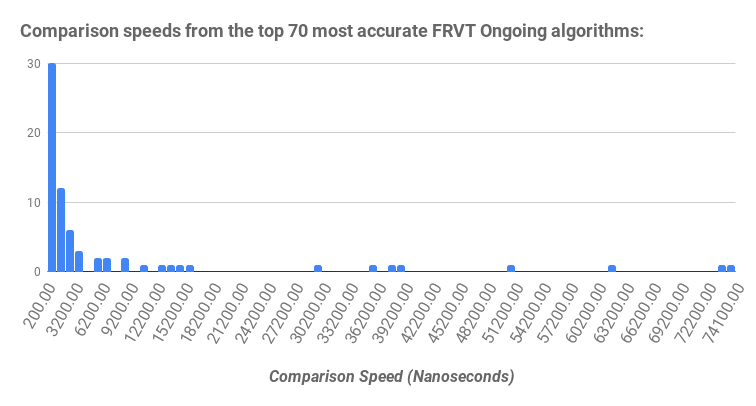
In NIST FRVT Ongoing, top-tier vendors vary in comparison speeds from 300 nanoseconds (ns) to 75,000ns, as illustrated in the above histogram. This is a difference of 250x between the two extremes of top accuracy vendors. Typically this indicates a 250x difference in search speeds, or significantly more CPU cores needed to enable a timely search.
Consider searching a 10M template database with a single CPU core. With a 300ns comparison time it would take: 300e-9 * 10e6 = 3 seconds. With a 75,000ns comparison time it would take 750 seconds, or 12.5 minutes, a staggering difference between otherwise similar algorithms.
It is worth noting that there is a strong correlation between template size and comparison speed. For example, in the most recent NIST FRVT Ongoing, the correlation coefficient between template size and comparison speed for the 99 algorithms benchmarked is 0.835.
Binary size
In addition to loading templates into RAM, the face recognition software itself will occupy a generally fixed amount of memory. The memory used by a face recognition software comprises of (i) code libraries and (ii) statistical models.
While some face recognition software development kits (SDKs) are carefully implemented to minimize software libraries, others have not been designed with this consideration. Thus, there could be a difference between 10MB of RAM used for one implementation’s code, and 1GB used for another. SDKs and systems with larger libraries may also have more dependencies that make them harder to package and install.
Unfortunately NIST FRVT does not currently measure algorithm binary size.
The models used by a face recognition algorithm are the parameters learned through the offline statistical learning process employed by face recognition vendors. As every viable face recognition algorithm uses machine learning (often referred to as “AI”), every vendor will have models that need to be loaded into RAM in order to enroll images to templates.
NIST FRVT does measure the model size, though there are a few issues with how this is currently reported (e.g., Rank One’s model size is reported as 0 bytes as opposed to roughly 40MB). Regardless, model size ranges from 50MB to 4GB in the November FRVT Ongoing report, which is a tremendous difference.
The binary size of an SDK becomes particularly important for embedded devices. If an algorithm requires 4GB of RAM, it is generally not possible to use it on low cost embedded devices such as mobile phones, access control devices, doorbells, automobiles, and many other consumer electronic devices that are adding face recognition technology stacks. For many of these applications the face recognition algorithm is but one of several features, and it is often limited to less than 100MB (or even 10MB) of RAM.
Applications
With these four different efficiency metrics established, we will help tie these considerations back to applications.
- Template size will impact how many images are searchable on a machine with a fixed amount of RAM.
- Comparison speed will impact how long it takes to receive search results.
- Enrollment speed will impact how long it takes to initially index or later upgrade a database.
- Enrollment speed will impact how long it takes a system to process a request.
- Enrollment speed will impact how much power is consumed, which is particularly important for battery powered devices.
- Binary size will impact how much RAM is required, which is often limited in embedded devices.
- Enrollment speed will impact how many CPU cores are required to process a camera feed.
- Template size will impact how large of a watch-list can be searched.
- Comparison speed will impact how long it takes to generate match-alerts.
- Template size will impact how many images are searchable on a machine with a fixed amount of RAM.
- Comparison speed will impact how long it takes to receive search results.
- Enrollment speed will impact how long it takes to initially index or later upgrade a database.
Summary
The efficiency of a face recognition algorithm can significantly affect the hardware cost of an application, or even whether the application can be built in the first place. There are four efficiency metrics to consider when procuring a face recognition algorithm: enrollment speed, template size, comparison speed, and binary size. And, while there is a wide range of face recognition algorithms with similar accuracy, there can be a massive differences in efficiency across these algorithms.
Before you begin the process of integrating and testing an algorithm, it is critical to understand how these different metrics may impact your application and to filter out any solutions that do not meet your hardware budget or application requirements.